Attention Is All You Need (2017) Explained
Aug, 2021
@misc{vaswani2017attention,
title={Attention Is All You Need},
author={Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin},
year={2017},
eprint={1706.03762},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Why does everyone want Transformers all of a sudden?
One of the core concerns surrounding the typically used RNN models in NLP is the inability of the model to be parallelised. The architecture, by virtue of being sequential, are harder to train with distributed systems, particularly when working with long sequences or stateful RNNs, thereby not allowing us to make the full use of heavily distributed computational machinery that we have access to.
Then there’s also the concern of vanishing and exploding gradients. While not unique to RNNs, this has been a fairly prevalent problem even after introducing novel architectures and other methods for mitigation.
Third is the issue that sequential data works best with RNNs. This is true of many data types, audio, text, video, time series, pretty much anything that has anything to do with a sequence.
A new architecture itself was needed that could resolve the above problems.
Introducing the Transformer
What do you do when you need to build a new architecture, that solves the above problems? Well, as researchers at Google and University of Toronto found in their era-defining paper, Attention Is All You Need (2017), what you need is a model that
- Has massive capacity, but with only easily distributable operations. No, seriously. Massive.
- Makes use of attention each time, every time, over multiple processing heads.
- Looks simple at first glance, but every time you read the paper again reveals how nuanced and intricate the design is
Obviously, the above is an oversimplification from the eyes of a young man awestruck by how brilliantly designed this network is. Let’s dive a little deeper into the details.
NOTE: Some images haven’t been generated by me. Wherever required, I have mentioned the source of the image.
Alright, so I need Attention. What is attention, again?
RNNs were used because they knew how to remember what is important when. They knew how to remember that if we are looking at a word at a current timestep, there had to be a word in the past related to it. For example in the sentence His name is Adrian, the RNN knew that his refers to Adrian, and that name too refers to Adrian. RNNs do this by maintaining an internal hidden state.
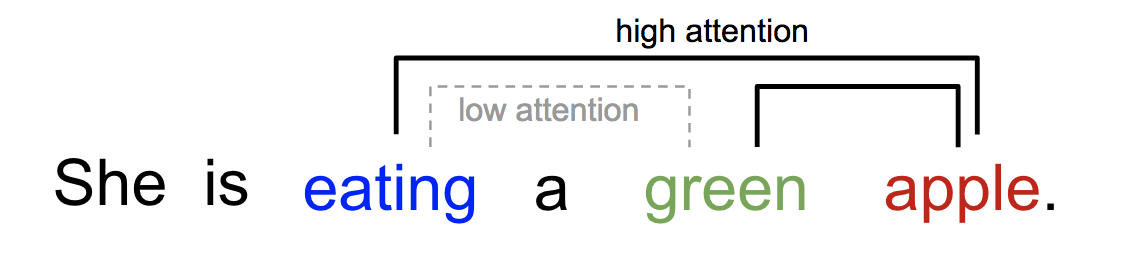 Example of Attention,
Image Source: Attention? Attention! By Lilian Weng, 2014
Example of Attention,
Image Source: Attention? Attention! By Lilian Weng, 2014
Of course, this became an issue once the RNN had provided its output to another RNN, particularly in encoder-decoder architectures. For instance, in the famous publication about the first encoder-decoder architecture, Sequence to Sequence Learning with Neural Networks (2014), the encoder-decoder architecture was able to translate languages very well, but the performance was still not optimal. They were passing the final state of the encoder to initialise the decoder states so that there would be some semantic information retained, but clearly it wasn’t enough.
That was until the paper Neural Machine Translation by Jointly Learning to Align and Translate (2014) came out. In this, in between the step where they pass the output of the encoder and decoder, an attention layer was used. While this attention layer isn’t the same as the one used in Transformers (more on this later), it proved that attention could definitely be a powerful tool to make use of in encoder-decoder architectures.
Please note that, for our case, we only speak about self attention, and each time we say attention we mean self attention
The major difference between attention and self attention is that attention is the general case that applies to two different entities, while self attention applies attention to the same entity
So, what is attention? Attention is basically a matrix that remembers how much correlation every word in the sentence has with every other word. Like in the example above, adrian would be highly correlated to name and his but his would not be highly related to name. Yeah, that’s pretty much it. This information is important since we cannot capture it via hidden states the way RNNs can. For more examples, you may refer to this amazing blog by Jay Alammar or the one by Lilian Weng
Can we move on to the transformer now please?
![]()
Transformer Network, Image Source: The Illustrated Transformer by Jay Alammar
{kind=link}
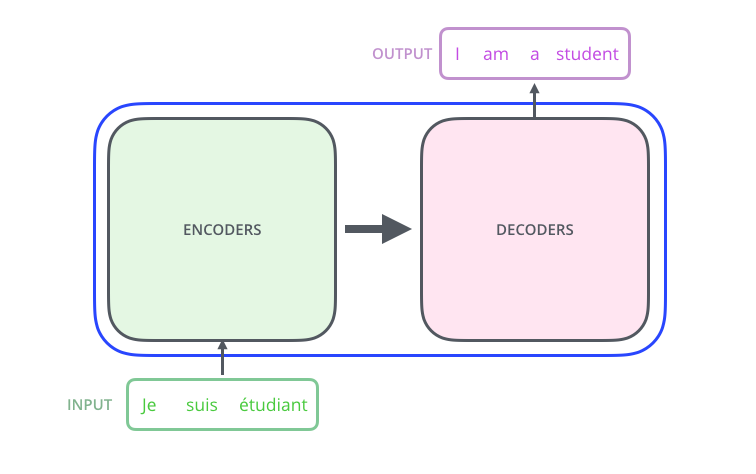
Okay so like any other encoder-decoder architecture, the Transformer network too makes use of a similar idea - the input is passed through the encoder, the encoder generates some output which it passes to the decoder. The decoder starts with an empty string, i.e. the <START_TOKEN>, passes it through the decoder, generates the next token, adds it to the sentence, and keeps predicting new tokens until it either hits the <END_TOKEN> or reaches maximum output sentence length.
This property of the Transformer, that it generates one token at a time to predict the next statement is called the AUTOREGRESSIVE property - it predicts future tokens basis its own predictions of past timesteps
When reading the section on decoding, please pay particular attention. If you are TensorFlow programmers like me, you will more than likely run into the same confusion I had after reading the official documentation
Now, the encoder does not only pass the output - it also needs to pass other semantic information. In the case of Seq2Seq, they passed the initial RNN state. In the case of Seq2Seq with attention, they passed the initial RNN state for the decoder as well as the attention layer. We will discuss what kind of semantic information is passed via the encoder later, but remembering that there is some kind of extra information being passed is important - it is one of the key innovations in the transformer network.
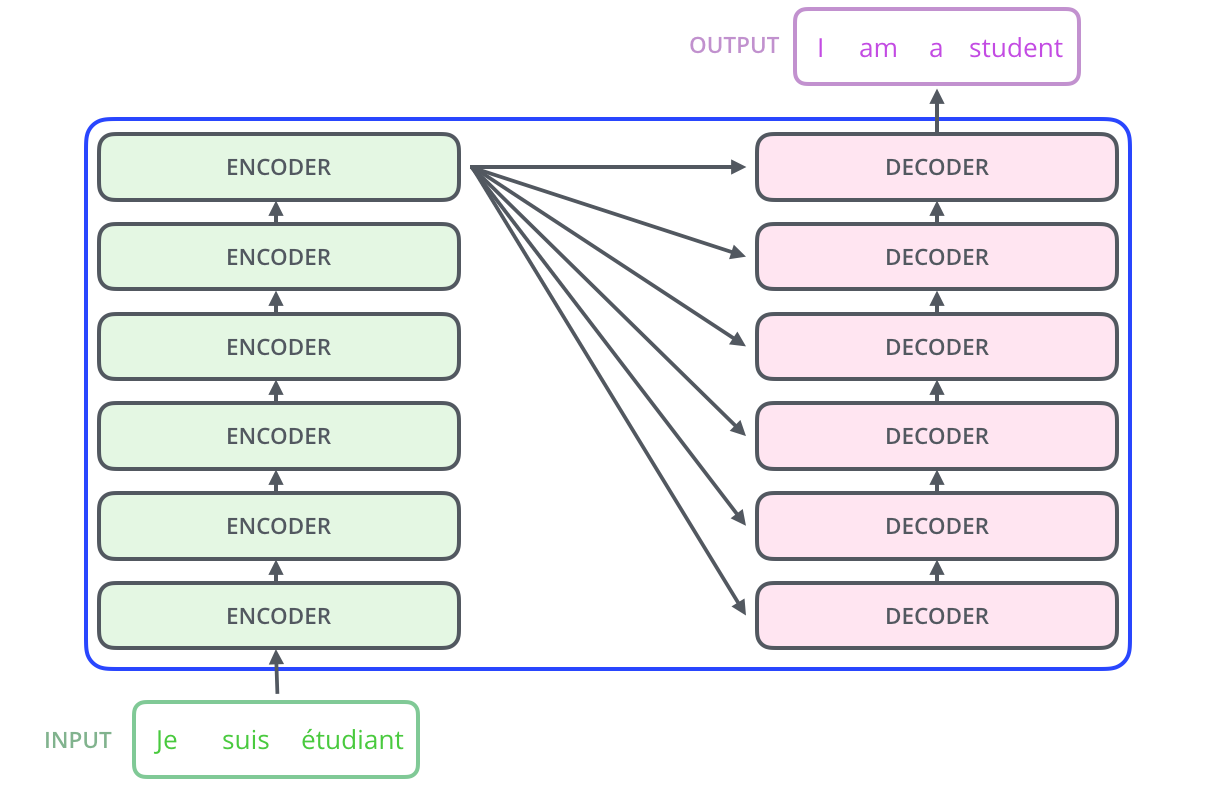
The layer named Encoders is in fact a stack of individual layers, each called an encoder layer. The same is the case with the decoders, as can be seen below.
![]()
Encoder & Decoder Stack, Image Source: The Illustrated Transformer by Jay Alammar
{kind=link}
The actual transformer model in itself looks like the below

Transformer Model, Image Source: Attention Is All You Need
For now, don’t think too much about the positional encoding and the various other numbers floating in the diagrams. I will take you through each step by step.
The Encoder and Decoder Layers
![]()
Encoder and Decoder Layers, Image Source: The Illustrated Transformer by Jay Alammar
{kind=link}
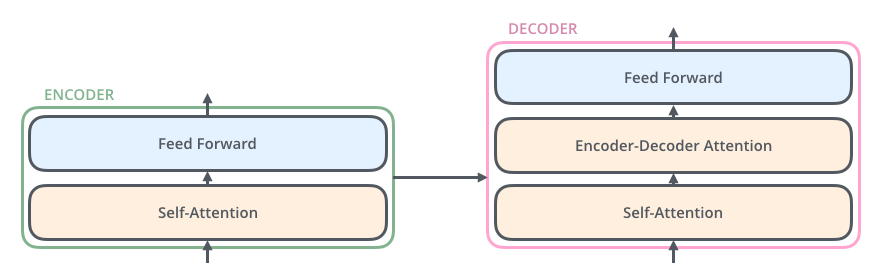
Each Encoder Layer can be broken into two main parts - the first, is the self attention layer, the second is a feed forward network. The authors recommend using 6 layers each of the encoder layers and decoder layers
The Decoder Layer has three parts, first is self attention, next is the encoder-decoder attention layer, and finally the feed forward network.
Remember when I said that there is some extra semantic information from the encoder going to the decoder? The encoder-decoder attention layer is where all the magic happens. We will discuss this further, but first we need to understand how the other layers are working.
Self Attention Layer
Before any attention mechanism can in fact occur, the authors of the paper recommended that in every encoder layer, there be not one, but multiple paths through which attention is calculated. What this means, is that the same input is taken and passed through multiple different attention layers (the output of which will be concatenated later). This, is known as Multiheaded Attention, where each path for attention is considered to be one head.

Multiheaded Attention, Image Source: Attention Is All You Need
Don’t worry about the the V, Q and K values that you’re seeing. I will now be explaining what that is.
Now that the values have been sent in via the various heads, we need to find the values of the attention for the sentence. To do this, the authors proposed a new attention score, which was calculated using the layers below

Scaled Dot Product Attention, Image Source: Attention Is All You Need
So now coming back to the values Q, K and V. These stand for Query, Key and Value vectors respectively. These are different vectors calculated so that the attention scores for each word can be calculated.
To calculate the three vectors, the input values are multiplied by three trainable weight matrices namely Wq, Wk, Wv. The output values are q, k, v. These output values are then inserted into the formula
attn_score = matrix_multiply(
softmax( matrix_multiply( q, transpose(k)) / square_root( dim(k) )), v
)
Yes, I am well aware this looks like a long formula, so instead of looking at this, just look at the diagram above which explains what happens when q, k and v have been found. The reason that the authors have made use of square root of dim_k is as follows
We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients To counteract this effect, we scale the dot products by square root of dk
Quoted From Attention Is All You Need
Having calculated the values from individual heads, the values are concatenated and passed through a linear layer to return the same dimensions as the input had.
Pointwise Feedforward Network
After calculating attention scores, we pass it through a feedforward network. The authors propose a custom layer with the Relu activation function as follows
FFN(x) = max(0, x*W1 + b1)*W2 + b2
Add & Norm
You must’ve noticed the Add & Norm layers in the diagrams. These layers are effectively skip connections. What they do is, is take the original input before inserting into the given layer, add it to the output, and normalise the entire thing.
![]()
Add & Norm, Image Source: The Illustrated Transformer by Jay Alammar
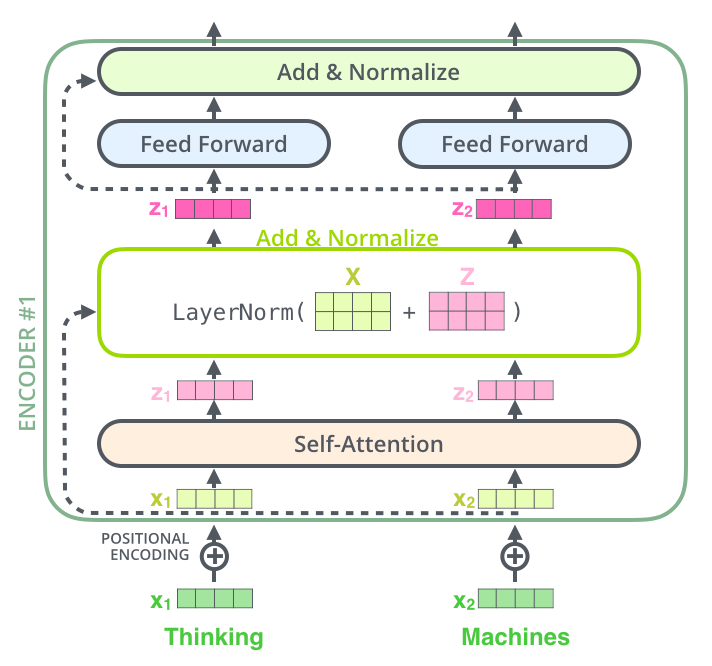{kind=link}
This is done to ensure that necessary semantic information prior to the processing is not lost in the due course of time, as well as to retain positional semantics, which we will discuss when we come across positional encoding.
Encoder Decoder Attention Layer
Finally, we find ourselves here. As I stated, there needs to be some semantic information flowing from the encoder to the decoder. In the decoder stack, the first and the last step remain the same. There is multiheaded attention with add & norm skip connection, and the last layer is the pointwise feedforward network. It’s the middle layer, the encoder-decoder attention layer where the magic happens.
The encoder creates some output. But the decoder’s inputs are starting with the empty string, i.e. with the <START_TOKEN>. So how exactly is the encoder sending information to the decoder?
In the encoder-decoder attention layer, the k, v values are not calculated using the decoder self attention layer values. Instead, the encoder provides the input for multiplication with Wk, Wv. The q value is however passed by the decoder output. Once this has been done, the rest of the process remains the same. Using the semantic information by calculating self attention from the encoder k, v values, the decoder is able to provide the appropriate outputs.
Final Layers
The final layers, as expected from any encoder decoder architecture, are a linear layer, followed by a softmax layer that predicts the probability of each token’s occurrence. Of course, at this point, we may also use other strategies, such as beam search decoding to predict the output probabilities.
Additional Concepts
Positional Encoding
One advantage that RNNs have is that they remember information timestep by timestep, and are fully aware of what input value occurred at what timestep. This is not the case with transformer networks. So far, we have seen no positional semantics being baked into the outputs. We achieve this by using positional encoding.
Positional Encoding basically entails adding an increasing sequence of values, that remains the same for a given timestep. So for example, we could simply add 0, 1, 2, 3, 4 for the first five timesteps. Eventually, as the network keeps training, it will learn that these deviations are occurring because there is some relative position between each timestep.
For the case of the transformer, the positional encoding is provided by

Positional Encoding Formula for Timestep i, Image Source: Attention Is All You Need
As the authors of the paper have quoted,
We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset k, PEpos+k can be represented as a linear function of PEpos
Quoted From Attention Is All You Need
Coming back to the reason for the residual skip connections, it is done to ensure some amount of this positional encoding continues to flow through the network and isn’t lost
Masking
Another issue with the inputs of the transformers is that when applying attention, you do not want to be applying attention to tokens that do not in fact exist, or are yet to be calculated.
In the case of encoder, if the max sequence length for a sentence is 128, but the currently observed sentence is only 64 tokens long, trying to apply attention to the remaining 64 tokens, which do not exist, will cause error in both training & inference, and will only increase training time and time taken for convergence.
Instead, the authors have suggested masking out these empty values with 0s when applying self attention in encoder layers. This mask, is referred to as the Padding Mask, because we are masking out the padding tokens applied to input sequences.
In the case of the decoder, we do not want the decoder to randomly look at the tokens that do not exist, since at step 0, the input is only <START_TOKEN>, and the remaining tokens do not exist. At each timestep, we will find a new token. Therefore, at the next timestep, we need to mask out max_seq_len - 2 tokens, and so on for each timestep.
This mask, is referred to as the Lookahead Mask since it disallows looking into the future for tokens that don’t exist.
Teacher Forcing
Why should RNNs have all the fun? Teacher forcing is also possible with Transformer networks. We simply pass the known output sequence as the decoder input, and get it to predict the entire sentence instead of doing it one token at a time. A good example for this would be the official TensorFlow tutorial on Transformers, where during training they have used teacher forcing but during evaluation, the loop is similar to what you would expect if you had to train it the routine way.
Important Mentions
Transformers have fundamentally changed the way NLP works, with many major organisations creating their own models that utlize this sophisticated architecture. I will be naming a few of the prominent ones but this isn’t by far a complete list